SMACK! Dieses zur Zeit noch relativ unbekannte Akronym ist gleichzeitig das aktuell vielleicht wichtigste im Big Data Umfeld. Das JavaMagazin 7.16 titelte unlängst “Die neue Generation Big Data. Doch wofür steht SMACK? Wie spielen die einzelnen Teile zusammen? Welche Probleme lassen sich dadurch lösen? Und wie (schnell) lassen sich erste Erfolge erzielen? Das wollte ich am eigenen Leib erfahren und machte mich vor einigen Wochen auf, etwas Licht ins Dunkle zu bringen. Allgemeine Fragestellungen zum Thema Stream-/Batchprocessing und einige der verwendeten Technologien waren mir zumindest namentlich bekannt – Hands-On Erfahrung hatte ich jedoch noch keine. Meine Erfahrungen möchte ich an dieser Stelle teilen.
Was ist der SMACK! Stack überhaupt?
SMACK steht für die einzelnen Komponenten [S]park, [M]esos, [A]kka, [C]assandra & [K]afka, jeweils Open Source Projekte, die ihrerseits bereits größere Bekannheit genießen und in den letzten Jahren immer relevanter geworden sind.
Abbildung 1: Google Trend – 5 Jahre
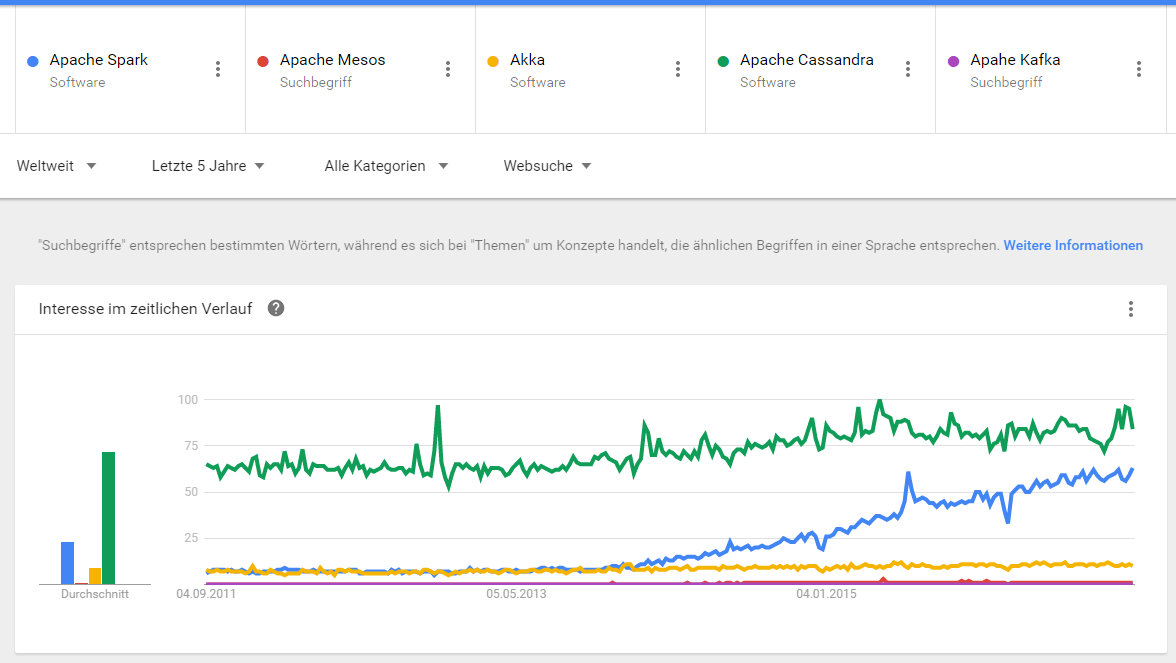
Abbildung 2: Google Trend – 2 Jahre

"Smack" klingt griffig – dennoch macht es Sinn, die einzelnen Technologien in einer anderen Reihenfolge vorzustellen. Wir beginnen mit [M]: Mesos. Mesos abstahiert Ressouren wie CPU oder RAM von physischen oder virtualisierten Maschinen und ermöglicht so den Betrieb verteilter, fehlertolerante und skalierbare Anwendungen auf einer höheren Abstraktionsebene. Wir verwenden nachfolgend Mesos als Bestandteil von DC/OS. DC/OS steht für Datacenter Operating System und umfasst neben Mesos (zur Ressourcen Abstraktion) zusätzlich Marathon (zur Initialisierung und Orchestrierung von Container-basierten Anwendungen) und ZooKepper (zur Leader-Auswahl).
Mesos abstahiert Ressouren wie CPU oder RAM von physischen oder virtualisierten Maschinen und ermöglicht so den Betrieb verteilter, fehlertolerante und skalierbare Anwendungen auf einer höheren Abstraktionsebene. Wir verwenden nachfolgend Mesos als Bestandteil von DC/OS.
DC/OS steht für Datacenter Operating System und umfasst neben Mesos (zur Ressourcen Abstraktion) zusätzlich Marathon (zur Initialisierung und Orcestrierung von Containerbasierten Anwendungen) und ZooKepper (zur Leader-Auswahl). Außerdem kommt DC/OS mit einem modernen User Interface und einer Vielzahlzertifzierten Services wie Chronos, Jenkins oder den eingangs erwähnten Spark, Cassandra und Kafka daher. Diese können per Mausklick oder über die Command Line installiert werden. Eigene Container-basierte Anwendungen könnnen mit Hilfe von JSON ebenfalls über Marathon deployt werden. Im SMACK Kontext kann DC/OS als Betriebssystem verstanden werden, auf welchem die weiteren Anwendungen laufen.
Akka ist ein Framework für Nachrichten-getriebene, reaktive Anwendungen und setzt das Aktorenmodell auf der JVM um. Im SMACK Kontext ist Akka für das auf-/entgegennehmen der Daten zuständig. Dabei handelt es sich meist um Streams oder Stream-ähnliche Datenquellen, wie z.B. regelmäßige HTTP-Abfragen.
Kafka ist ein verteilter, publish-subcribe basierter Message Broker und zuständig für das Entgegennehmen und Bereitstellen eingehender Nachrichten für die weitere Verarbeitung. In der SMACK Architektur hält Kafka die von Akka Actors übergebenen Nachrichten/Events und hält diese für die nachfolgende Verarbeitung mit Spark bereit. Kafka fungiert also als eine Art Puffer zwischen externen Streaming APIs und der internen Verarbeitung.
Cassandra ist eine verteilte, fehltertolerante, spaltenorientierte NoSQL Datenbank mit linearer Skalierbarkeit. Bei SMACK ist Cassandra für die Persistierung eingehender Daten und Zwischenergebnisse zuständig.
Spark ist ein Framework zur Datenverarbeitung. Spark ist cluster-basiert und dadurch hoch skalierbar. Die Berechnungen geschehen dabei zum Großteil In-Memory und dadurch schneller als bei klassische Frameworks mit viel I/O, wie Hadoop. Im SMACK Kontext ist Spark für Berechnungen aller Art zuständig. Dabei können sowohl Batch-, als auch Streaming-basierte Berechnungen Anwendung finden. Spark eignet sich gut für Architekturen, bei denen sowohl Batch-, als auch Streamingverabeitung stattfindet, da beide auf den selben Datenstrukturen operieren können. Es kann also der selbe Code für beide Anwendungsfälle verwendet werden.
Das Ganze ist mehr als die Summe seiner Teile
Alle vorgestellten Technologien sind vom Design her verteilt, Cluster-zentriert und laufen auf der JVM, wodurch die gegenseitige Integration gefördert wird. Auch wenn es teils High Level APIs in unterschiedlichen Sprachen (z.B. für Spark neben Scala und Java auch noch Python und R) gibt, macht es Sinn zumindest Java und Scala zu beherrschen, wenn man die Funktionalität nachvollziehen will oder Probleme lösen muss, die nicht über die High Level API gelöst werden können.
Wie schnell lässt sich nun ein einfaches Beispiel realisieren? Da ein ‘Hello World’ im Kontext verteilter, hochskalierbarer und fehlertoleranter Frameworks nur bedingt Sinn macht und auch das Big Data-typische Word Count den SMACK Möglichkeiten nicht gerecht wird, habe ich neue Beispiele gesucht. Dabei bin ich unter anderem auf Blogeinträge von Codcentric gestoßen. Codecentric ist einer der Vorreiter im deutschsprachigen Raum für den SMACK Stack und im eingangs erwähnten JavaMagazin 7.16 mit vier Artikeln vertreten.
Der erste Blogeintrag, der mich ansprach war ‘Der SMACK-Stack zum Anfassen!‘ auf der Blogseite von codecentric.
Dieser war gerade frisch erschienen und schien ein guter Eintrittspunkt zu sein.
Versuch Nr.1 – ‘Der SMACK-Stack zum Anfassen’
Zu Beginn waren mir alle im Artikel vorkommenden Technologien fremd, weshalb ich begann mich mit den unter Vorbedingungen aufgelisteten Technologien Vagrant, Virtualbox und Ansible auseinanderzusetzen. Diese werden in diesem Beispiel für die automatisierte Erstellung des DC/OS Clusters verwendet.
Ich begann ich mit dem Einlesen und bemerkte relativ schnell, dass diese DevOps-getriebenen Technologien für mich nur bedingt relevant waren. Ich wollte mich vorerst mit dem reinen SMACK Stack auseinandersetzen, weshalb ich mich nach einem gewonnen Grundverständnis dazu entschied mich nach anderen Tutorials umzusehen.
Im Rückblick (und ein gutes dutzend erstellter SMACK Stacks später) kann ich jedoch zum ersten Mal von einem echten eigenen Interesse bzgl. DevOps Technologien sprechen. Da ich außerdem ein gewisses Grundverständnis diesbezüglich gewonnen habe, sehe ich den kleinen Umweg positiv.
Die Suche nach einem anderen, mehr auf den SMACK Stack selbst konzentrierten, Tutorial führte mich in die direkte Nachbarschaft des ersten: Der Blogpost ‘SMACK Stack DC/OS Style‘, ebenfalls im Codecentric Blog beheimatet.
Versuch Nr.2: ‘SMACK Stack DC/OS Style’
Der Blogpost meines zweiten Anlaufs setzte einen DC/OS Cluster voraus. Da ich die Erstellung eines solchen zuvor nur im Kontext mit Vagrant, Virtualbox und Ansible kennengelernt habe, orientierte ich mich hier an der offiziellen Doku. Dabei habe ich die folgenden Schritte umgesetzt:
Erstellung eines DC/OS Clusters
Installation des DC/OS Command Line Interfaces
Installation der DC/OS Services
Erstellung eines DC/OS Clusters
Die verwendeten Maschinen sollten eine gewisse Leistungsfähigkeit haben. Mesos empfiehlt für Master und Slave Nodes in der Amazon Cloud mindestens m3.xlarge Instanzen. Eine m3.xlarge Instanz bietet ausbalancierte Datenverarbeitungs-, Arbeitsspeicher- und Netzwerkressourcen mit 4vCPU, 15GiB Arbeitsspeicher und 2x40GB SSD (siehe auch Amazon webserviles). Die Preise variieren von Region zu Region und unterliegen auch zeitlichen Schwankungen. Für eine m3.xlarge Linux Instanz in der Region US-EAST wurden Stand 1.9.2016 $0.266 pro Stunde berechnet. Für aktuelle Preise und zusätzliche Infos siehe auch aws.amazon.com/de/ec2/pricing/ .
Die Erstellung und Konfiguration der einzelnen Infrastrukturkomponenten kann gänzlich manuell über die AWS Console oder (teil-)automatisiert mit Hilfe unterschiedlicher Dienste geschehen. Hier seien exemplarisch Terraform und CloudFormation genannt. Zu den Vor- und Nachteilen der jeweiligen Lösung gibt es online bereits einige Einträge, z.B. auf upguard.com. Auf den ersten Blick scheint sich der Funktionsumfang zu ähneln.
Da die Erstellung des DC/OS Clusters mit Hilfe von CloudFormatoin Templates fast automatisch geschieht (man muss zusätzlich einen Namen und ein zu verwendendes Schlüsselpaar; außerdem können optional zusätzliche Variablen übergeben werden), habe ich mich für die CloudFormation Variante entschieden. Dabei werden zwei unterschiedliche Templates angeboten: Das ‘normales Template mit einem Master Node und das hochverfügbare Template mit drei Master Nodes. Die Templates sind dabei Region-spezifisch und hier zu finden.
Da mein Experiment keine Hochverfügbarkeit verlangt, habe ich mich für die ‘normale’ Variante mit 1 MasterNode entschieden – auch, um die Kosten gering zu halten. Eine Beispielkalkulation ist zum Beispiel hier zu finden.
Das CloudFormation Template verwendet neben den m3.xlarge Instanzen noch einige weitere Infrastrukturkomponenten – SecurityGroups, DHCPOPtions, NATInstances, RouteTables, S3::Buckets, IAM::Roles und einige mehr. Es werden daher Berechtigungen für ein S3 Bucket und Identity and Access Management (IAM) benötigt. Das CloudFormation Template ist dabei sehr komplex und besteht aus immerhin 2388 Zeilen formatiertem JSON. Für zusätzliche Infos zu CloudFormation auf AWS siehe auch aws.amazon.com/de/cloudformation.
Nachdem der Cluster auf der AWS Infrastruktur erfolgreich erstellt wurde, gilt es nun, diese ansprechbar zu machen. Dies ist zum einen über das User Interface möglich. Da wir später jedoch auch unter anderem einen Sparkjob laufen lassen (und hierzu eine .jar deployen wollen), wird zusätzlich noch das DC/OS Command Line Interface benötigt. Hier habe ich mich ebenfalls an der offiziellen Doku orientiert.
Installation des DC/OS Command Line Interface
Um das DC/OS CLI installieren zu können, müssen auf dem Notebook unter anderem git, Python, pip und virtualenv installiert sein. Je nach Betriebssystme variieren dabei die einzelnen Schritte.
Achtung: Die offizielle Doku gibt als Vorraussetzung “Python 2.7.x or 3.4.x” an – dies kann bei späteren Installation des DCOS-Spark Services via DC/OS CLI zu Problemen führen, da Python 2.7.6 (z.B. bei Ubuntu 14.04) zu einem Problem mit SSLV3 Handshake führt (siehe auch Listing 1).
Listing 1: Stacktrace Installation DCOS-Spark mit Python 2.7.6
jens@jens-VirtualBox:~/dcos$ dcos --log-level=ERROR package install spark
Installing Marathon app for package [spark] version [1.0.1-2.0.0]
Installing CLI subcommand for package [spark] version [1.0.1-2.0.0]
MainThread: 2016-08-16 18:46:02,286 /home/jens/dcos/local/lib/python2.7/site-packages/dcos/subcommand.py:_execute_command:581 - Command script's stdout: Collecting dcos-spark==0.5.19 from https://downloads.mesosphere.com/spark/assets/dcos_spark-0.5.19-py2.py3-none-any.whl (from -r /tmp/tmpiBB8IP (line 1))
MainThread: 2016-08-16 18:46:02,287 /home/jens/dcos/local/lib/python2.7/site-packages/dcos/subcommand.py:_execute_command:582 - Command script's stderr: /home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/_vendor/requests/packages/urllib3/util/ssl_.py:318: SNIMissingWarning: An HTTPS request has been made, but the SNI (Subject Name Indication) extension to TLS is not available on this platform. This may cause the server to present an incorrect TLS certificate, which can cause validation failures. You can upgrade to a newer version of Python to solve this. For more information, see https://urllib3.readthedocs.org/en/latest/security.html#snimissingwarning.
SNIMissingWarning
/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/_vendor/requests/packages/urllib3/util/ssl_.py:122: InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. You can upgrade to a newer version of Python to solve this. For more information, see https://urllib3.readthedocs.org/en/latest/security.html#insecureplatformwarning.
InsecurePlatformWarning
Exception:
Traceback (most recent call last):
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/basecommand.py", line 215, in main
status = self.run(options, args)
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/commands/install.py", line 310, in run
wb.build(autobuilding=True)
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/wheel.py", line 750, in build
self.requirement_set.prepare_files(self.finder)
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/req/req_set.py", line 370, in prepare_files
ignore_dependencies=self.ignore_dependencies))
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/req/req_set.py", line 587, in _prepare_file
session=self.session, hashes=hashes)
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/download.py", line 810, in unpack_url
hashes=hashes
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/download.py", line 649, in unpack_http_url
hashes)
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/download.py", line 842, in _download_http_url
stream=True,
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/_vendor/requests/sessions.py", line 487, in get
return self.request('GET', url, **kwargs)
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/download.py", line 378, in request
return super(PipSession, self).request(method, url, *args, **kwargs)
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/_vendor/requests/sessions.py", line 475, in request
resp = self.send(prep, **send_kwargs)
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/_vendor/requests/sessions.py", line 585, in send
r = adapter.send(request, **kwargs)
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/_vendor/cachecontrol/adapter.py", line 46, in send
resp = super(CacheControlAdapter, self).send(request, **kw)
File "/home/jens/.dcos/subcommands/spark/env/local/lib/python2.7/site-packages/pip/_vendor/requests/adapters.py", line 477, in send
raise SSLError(e, request=request)
SSLError: [Errno 1] _ssl.c:510: error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failure
Error installing 'spark' package.
Run with `dcos --log-level=ERROR` to see the full output.
Lösung: Update auf Python 2.7.11 (z.B. bei Ubuntu 16.04).
Installation Services
Anschließend werden die einzelnen Services über das DC/OS User Interface per Mausklick installiert. Da wir aber Spark Jobs ausführen wollen und diese irgendwie deployen müssen, müssen wir zumindest Spark auch per CLI ansprechen können, weshalb hier die Installation über DC/OS CLI sinnvoller erscheint. Wer dennoch das wirklich hübsche User Interface verwenden möchte, der kann die entsprechende DC/OS CLI utility auch nachträglich installieren – z.B. dcos package install spark –cli)
dcos package install spark
dcos package install cassandra
dcos package install kafka
dcos package install chronos
Chronos ist das ‘cron’ für DC/OS und kann für das Triggern unterschiedlichster Jobs verwendet werden – in diesem Szenario wird ein Chron Job erzeugt, welcher Cassandra mit einem Schema initialisiert
Deployment eigener Anwendungen
Nun, da die benötigte Infrastruktur/Services zur Verfügung stehen – wie bringen wir unsere eigenen Anwendungen ein?
Zuerst initialisieren wir Cassandra mit einem Schema. Dies wird, wie bereits beschrieben, mit Hilfe eines Chronos Jobs erledigt. Der Job benötigt ein Docker Image und wir verwenden hierzu die Chronos REST API. Man kann auch curl oder einen beliebigen anderen REST Client verwendet.
Achtung: Windows User, welche die Powershell verwenden, können auf Probleme stoßen: Die Powershell kommt standardmäßig mit einem curl Alias für das Windows-eigene Command Invoke-WebRequest, welches einen deutlich geringeren Funktionsumfang bietet, siehe auch https://daniel.haxx.se/blog. Will man curl verwenden, so muss man das alias entfernen (und curl natürlich der Powershell bekannt sein).
Zusätzliche Anwendungen können mit Hilfe von Marathon deployt werden. Wenn man DC/OS verwendet, dann läuft Marathon automatisch auf dem Master Node. Marathon startet und überwacht die auf DC/OS laufenden Services und Anwendungen .
Das Deployment von (Container-basierten) Anwendungen geschieht dabei mit Hilfe von JSON Files. Ein simples Beispiel für das Deployment einer in einem DOCKER Container laufenden Anwendung ist in Listing 2 abgebildet.
Wie in Listing 2 zu sehen, werden neben einer ID die für die Anwendung benötigten Ressourcen und eine Container-Definition benötigt. Außerdem können Umgebungsvariablen mitgegeben werden. Über die Umgebungsvariablen werden die separat auf dem Cluster deployten Services und Anwendungen in der Regel über Host/IP und Port miteinander verknüpft.
Listing 2: Beispieldeployment.json
{
"id": "/some-demo-ingest",
"cpus": 1,
"mem": 2048,
"disk": 0,
"instances": 1,
"container": {
"type": "DOCKER",
"volumes": [],
"docker": {
"image": "dibuco/some-demo-ingest",
"network": "HOST",
"privileged": false,
"parameters": [],
"forcePullImage": true
}
},
"env": {
"CASSANDRA_HOST":"1.2.3.4",
"CASSANDRA_PORT":"4711",
"KAFKA_HOST":"6.7.8.9",
"KAFKA_PORT":"55555"
}
Die Ingestion Anwendung ist für das Einspeisen der externen Daten (regelmäßige HTTP Abfragen auch ein ‘echter’ Stream, wie z.B. der von Twitter) in unser System zuständig. Jedes eintreffende Event soll zum einen in Cassandra gespeichert und zum anderen in Kafka für die weitere Verarbeitung (mit Spark) geschrieben werden. Um die Kommunikation mit Cassandra und Kafka zu ermöglichen werden daher der jeweilige Host und Port mitgegeben.
![]()
Das zu deployende Docker Image befindet sich dabei z.B. auf DockerHub.
Der Code für das Docker Image kann in einem Git Repository verwaltet werden. Dies ermöglicht es, das Docker Image bei Codeänderungen automatisch zu updaten. Bisher werden BitBucket und GitHub unterstützt. Da eine Interaktion der einzelnen Docker Images, wie in Listing 2 gezeigt, in der Regel über zur Entwicklungszeit unbekannte (und potenziell mehrere, sich verändernde) Umgebungsvariablen geschieht, muss dies bei der Entwicklung berücksichtigt werden.
Achtung: Das im Blogpost verwendetes Image (codecentric/bus-demo-schema) lässt sich Stand 1.9.2016 nicht mehr deployen. Hintergrund ist folgender: Der Cassandra DCOS Service wird bei der Installation aus dem GitHub Repository erstellt. Das Docker Image ist für diese neue Version nicht ausgelegt. Das Docker Image verwendet die CQL Version 3.3.1, während der DCOS-Cassandra-Service bereits CQL Version 3.4.0 verwendet. Ein Deployment-Versuch führt zu einem Connection Error:
Connection error: (‘Unable to connect to any servers’, {‘10.0.2.185’: ProtocolError(“cql_version ‘3.3.1’ is not supported by remote (w/ native protocol). Supported versions: [u’3.4.0′]”,)})
Eine mögliche Lösung um die CQL Version im Docker Image anzupassen ist in Listing 3 vorgestellt.
Listing 3: Anpassung des Docker Imagesdocker pull codecentric/bus-demo-schema # lädt das imagedocker run -t -i --entrypoint=/bin/bash codecentric/bus-demo-schema # startet das image mit einer bash (statt des entrypint.sh)# Ab hier in der shell des docker images agieren#########apt-get install nanonano /etc/apt/sources.list #oder anderweitig editieren und die folgenden Zeilen hinzufügendeb http://www.apache.org/dist/cassandra/debian 37x main # hier die gewünschte cassandra version eintragen: http://cassandra.apache.org/download/deb-src http://www.apache.org/dist/cassandra/debian 37x mainapt-get updateapt-get dist-upgrade # cassandra update# evtl. mussjava 8 noch installiert werdenexit #beendet den container# Ab hier wieder außerhalb des docker images agieren############ https://docs.docker.com/engine/tutorials/dockerimages/#creating-our-own-imagesdocker commit -m "Cassandra update" c3e2f40ecf55 codecentric/bus-demo-schema:v2
Starten des Spark Jobs
Das letzte Puzzlestück des Blogposts ist das Starten des Spark Jobs. Dieser wird über die DC/OS CLI gestartet
(dcos spark run –submit-args=’–supervise -Dspark.mesos.coarse=true –driver-cores 1 –driver-memory 1024M –class de.nierbeck.floating.data.stream.spark.KafkaToCassandraSparkApp https://s3.eu-central-1.amazonaws.com/codecentric/big-data/bus-demo/bus-demo-digest-assembly-0.1.0.jar METRO-Vehicles $CASSANDRA_HOST $CASSANDRA_PORT $KAFKA_HOST $KAFKA_PORT’).
Achtung: Das Starten eines Spark Jobs via DC/OS CLI funktioniert aktuell nur unter Linux. Windows Nutzern ist es durch einen Bug nicht möglich, Spark Jobs zu starten, da eine Linux-spezifische Abfrage nach den Berechtigungen des dcos Konfigurationsfiles einen Fehler wirft: dcos.errors.DCOSException: Permissions ‘0o666’ for configuration file ‘C:\Users\Jens\.dcos\dcos.toml’ are too open. File must only be accessible by owner. Aborting…
Hierzu wurde bereits ein entsprechendes Ticket erstelllt: https://dcosjira.atlassian.net/browse/DCOS-279
Wenn das Starten eines Spark Jobs jedoch erfolgreich ist, dann können mit diesem unterschiedlichen Analysen durchgeführt werden. Der Spark Job in diesem Beispiel hätte mit Hilfe des “Density-Based Clustering in Spatial Databases” (DBSCAN)-Gruppierungs-(Clustering)-Algorithmus Bus-Cluster berechnet. Als Inspiration diente Codecentric der Blog von Natalino Busa, auf den an dieser Stelle daher ebenfalls hingewiesen sei.
Fazit und Ausblick
Beim SMACK Stack greifen viele unterschiedliche Technologien ineinander. Da eine Änderung an einer Komponente Auswirkungen auf die angrenzenden Technologien haben kann, müssen alle Teile verstanden werden. Außerdem spürt man die Aktualität: Es gibt fast täglich, zumindest aber wöchentlich, neue Commits. Nur, weil etwas Freitagabend läuft, heißt das also noch lange nicht, dass es auch Montagmorgen noch funktioniert. Dadurch bedarf auch die Umsetzung simpler Beispiele ein verhältnismäßig gutes Verständnis.
Gleichzeitig greifen die einzelnen Technologien intuitiv ineinander und funktionieren gut zusammen. Dies liegt u.a. auch daran, dass sie aufeinander aufbauen und Mesos der favorisierte Ressourcen Manager für die weiteren Sevices ist. Hier sei als mögliche Alternative aufYARN verwiesen. Dass die Anwendungen auch in großen Systemen gut zusammenspielen, muss sich erst noch beweisen. Für sich genommen ist jede Anwendung bereits heute in großen Systemen im Einsatz.
Ich bin gespannt, was die Zukunft bringen wird. Dabei beschränke ich mich nicht auf den SMACK Stack alleine, sondern auch auf Subsets desselben sowie die einzelnen Anwendungen selbst. Außerdem sind, je nach Kontext, angrenzende Technologien (z.B. Vagrant und Ansible für DevOps oder zusätzlich zu Zeppelin zur explorativen Datenanalyse.
Zum Schluss sind nochmal alle erwähnten Technologien
und ihr Zusammenspiel in Abbildung 3 dargestellt.
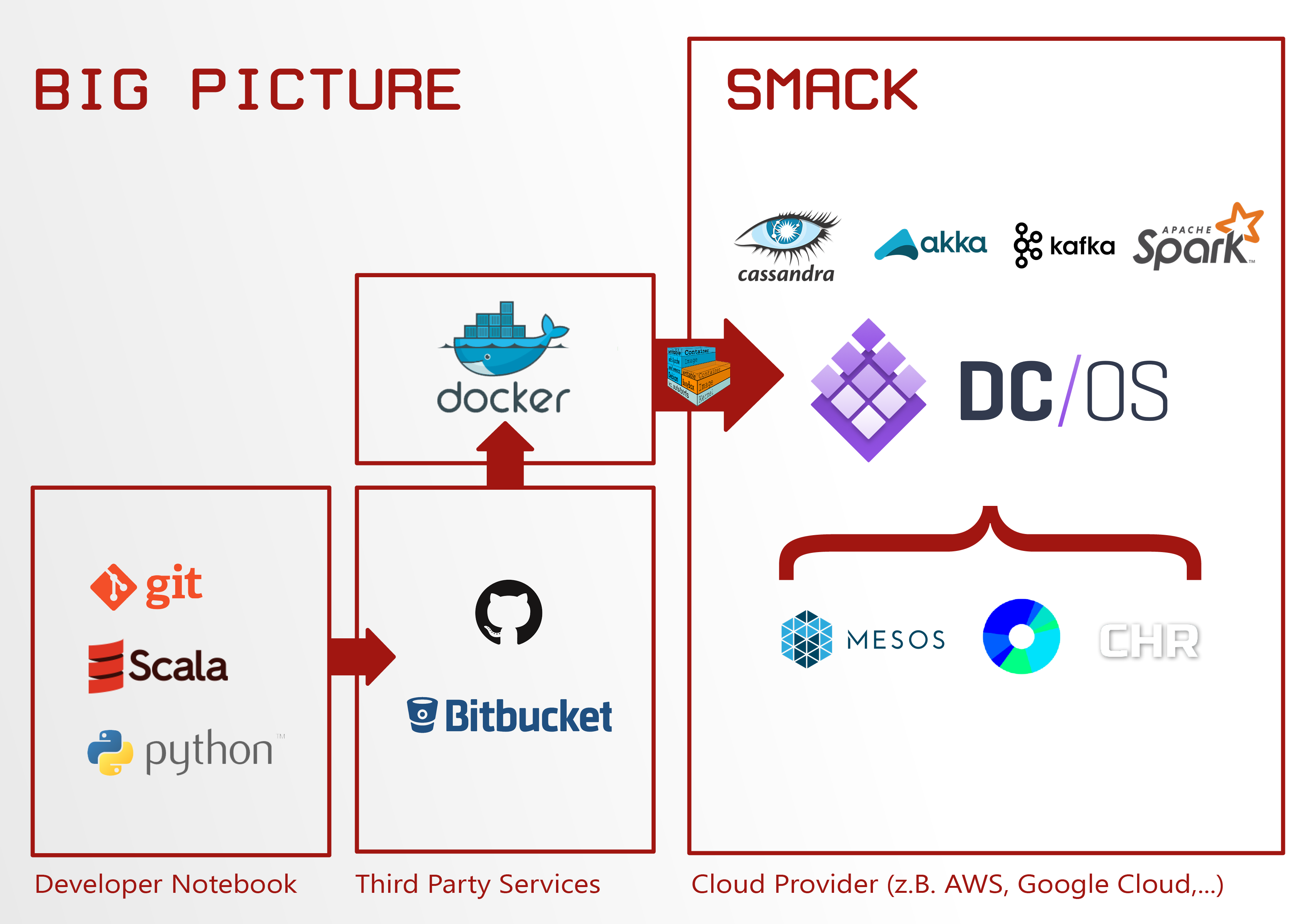
Abbildung 3: SMACK Big Picture (inkl. Angrenzender Technologien)
Bildquellen
- Google Trends: Google Trends
- Mesos: https://mesosphere.com/wp-content/themes/mesosphere/library/images/views/why-mesos/mesos-logo.png?v1
- DC/OS: https://mesosphere.com/wp-content/uploads/2016/04/logo-horizontal-styled.png
- Cassandra: https://upload.wikimedia.org/wikipedia/commons/thumb/5/5e/Cassandra_logo.svg/2000px-Cassandra_logo.svg.png
- Kafka: http://hortonworks.com/wp-content/uploads/2016/03/kafka-logo-wide.png
- Spark: http://spark.apache.org/images/spark-logo-trademark.png
- AKKA: https://upload.wikimedia.org/wikipedia/en/thumb/5/5e/Akka_toolkit_logo.svg/1280px-Akka_toolkit_logo.svg.png
- JavaMagazin: https://jaxenter.de/wp-content/uploads/2016/05/Java-Magazin-7-16_Cover_595x842-200×283.jpg
- Scala: https://upload.wikimedia.org/wikipedia/en/8/85/Scala_logo.png
- Git: https://git-scm.com/images/logos/1color-orange-lightbg@2x.png
- Python: https://www.python.org/static/community_logos/python-logo-master-v3-TM.png
- GitHub: https://assets-cdn.github.com/images/modules/logos_page/GitHub-Mark.png
- Chronos: https://mesosphere.com/wp-content/themes/mesosphere/library/images/components/services/chronos.jpg
- Marathon: http://blog.arungupta.me/wp-content/uploads/2016/05/apache-mesos-marathon-logo.png
- Ansible: https://upload.wikimedia.org/wikipedia/commons/0/05/Ansible_Logo.png
- Vagrant: https://upload.wikimedia.org/wikipedia/commons/8/87/Vagrant.png
- DockerHub: https://www.docker.com/sites/default/files/legal/small_v.png
- Docker Image: http://www.jayway.com/wp-content/uploads/2015/03/docker-image.png
- BitBucket: http://t1.gstatic.com/images?q=tbn:ANd9GcRqpPKn-VFjh4Lh35XbceeQaHPx3mzXJbsJqRWgVx3iBpA6BtnXrKD11g
- Notebook: https://upload.wikimedia.org/wikipedia/commons/f/fa/MacBook.jpg
- CloudFormation: http://www.myrtec.com.au/sites/www.myrtec.com.au/files/styles/company_logo_large/public/cformation.jpg?itok=4SsBgdfa
- Terraform: https://www.terraform.io/assets/images/logo_large-3e11db19.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
